



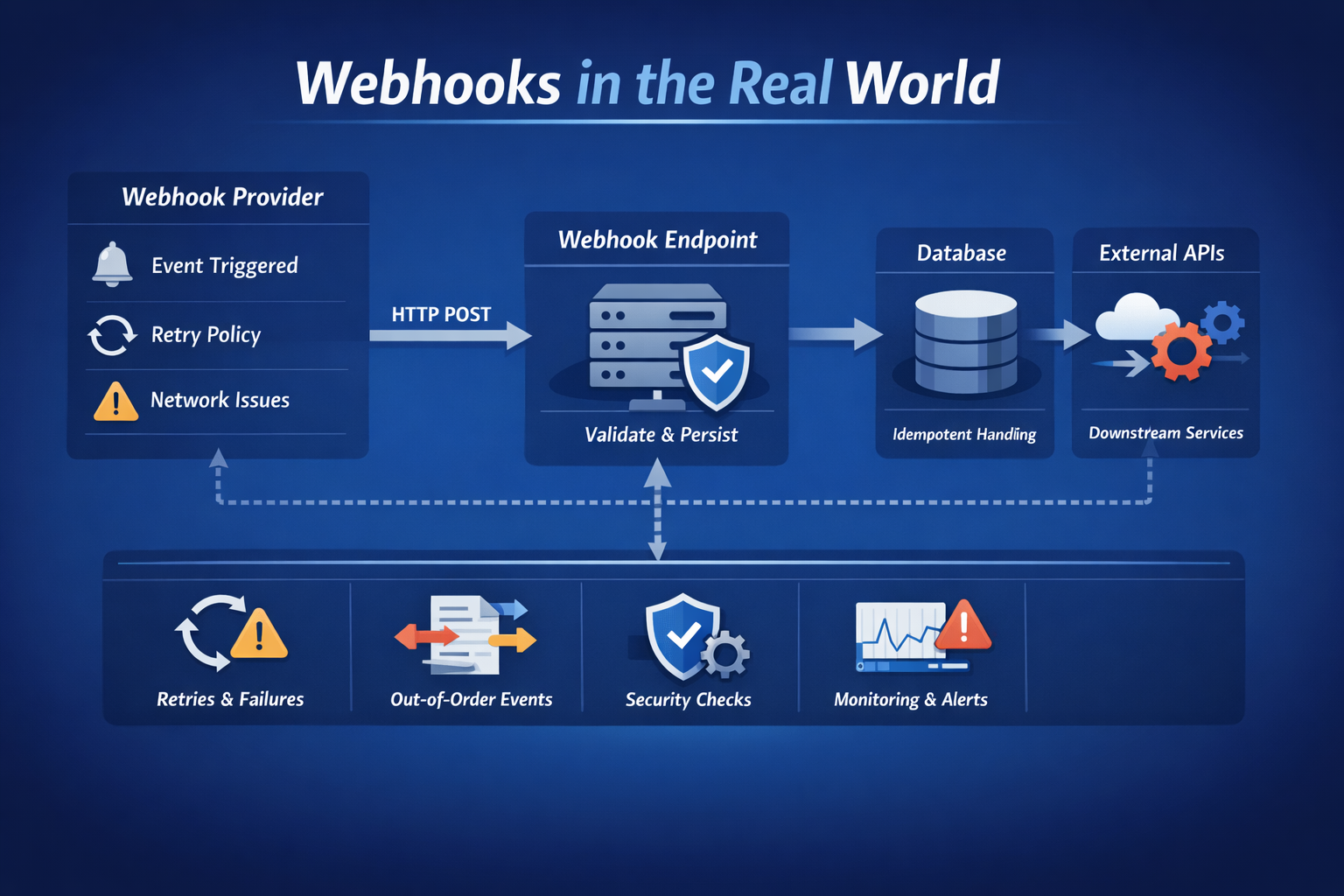
Webhooks går sönder i produktion när du antar perfekta förhållanden. Den här guiden går igenom verkliga utmaningar med webhooks; dubbla händelser, fördröjningar i bearbetningen, säkerhetsbrister och problem med händelseordning, och visar dig beprövade mönster som idempotens, asynkron bearbetning och signaturverifiering för att bygga robusta, produktionsklara webhook-system.
På papperet ser webhooks enkla ut.
Exponera en slutpunkt.
Ta emot en POST-förfrågan.
Bearbeta nyttolasten.
Returnera 200 OK.
Den mentala modellen fungerar under utveckling. Den överlever inte i produktion.
När verkliga system börjar kommunicera med varandra över opålitliga nätverk, slutar webhooks att bete sig som snygga HTTP-förfrågningar och börjar bete sig som problem i distribuerade system. Händelser återförsöks, dupliceras, fördröjs eller omordnas. Om din webhook-konsument antar perfekta förhållanden kommer den till slut att gå sönder.
Här är vad som brukar gå fel och de mönster som gör webhook-hanteringen pålitlig.
1. Hur förhindrar man dubbla webhook-händelser?
De flesta webhook-leverantörer försöker leverera igen om:
- Din slutpunkt får timeout
- En statuskod som inte är 2xx returneras
- Det uppstår ett tillfälligt nätverksproblem
Det betyder att samma händelse kan anlända flera gånger.
Om varje leverans blint utlöser affärslogik, kommer du så småningom att se duplicerade poster, ett inkonsekvent tillstånd eller upprepade sidoeffekter.
Lösningen: Webhook-idempotens
Webhook-hanterare måste vara idempotenta; att bearbeta samma händelse flera gånger ska inte ändra slutresultatet.
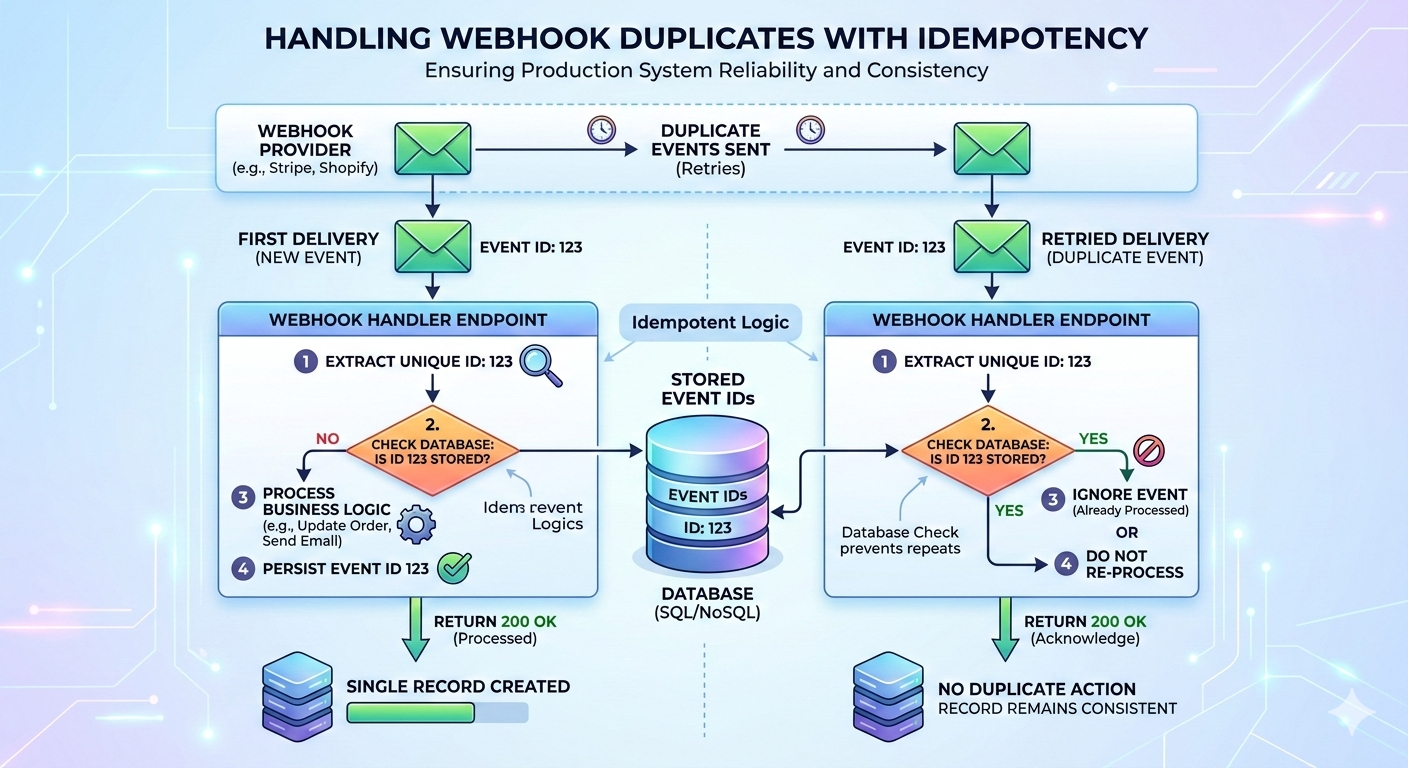
Det enklaste sättet att uppnå detta är:
- Säkerställ att varje händelse har en unik identifierare
- Lagra bearbetade händelse-ID:n
- Ignorera händelser som redan har hanterats
Exempel (Flask + SQLAlchemy-mönster):
def handle_webhook(event):
event_id = event["id"]
if db.session.query(WebhookEvent)
.filter_by(event_id=event_id).first():
return {"status": "already_processed"}, 200
process_event(event)
db.session.add(WebhookEvent(event_id=event_id))
db.session.commit()
return {"status": "processed"}, 200Med detta på plats blir återförsök ofarliga. Utan det blir återförsök incidenter.
2. Att bearbeta allt inuti webhook-rutten är riskabelt
Det är frestande att utföra all affärslogik direkt inuti webhook-rutten:
- Validera nyttolast
- Uppdatera databas
- Anropa nedströms tjänster
- Utlös arbetsflöden
Det fungerar tills belastningen ökar.
Om bearbetningen tar för lång tid kan leverantören anta ett fel och försöka igen, även om ditt system fortfarande fungerar. Detta ökar trafiken, vilket ytterligare saktar ner bearbetningen och skapar en återkopplingsslinga.
Lösningen: Bekräfta snabbt, bearbeta asynkront
Ett mer robust mönster är:
- Validera förfrågan
- Lagra den råa händelsen (databas eller kö)
- Returnera omedelbart 200 OK
- Bearbeta händelsen i en bakgrundsarbetare
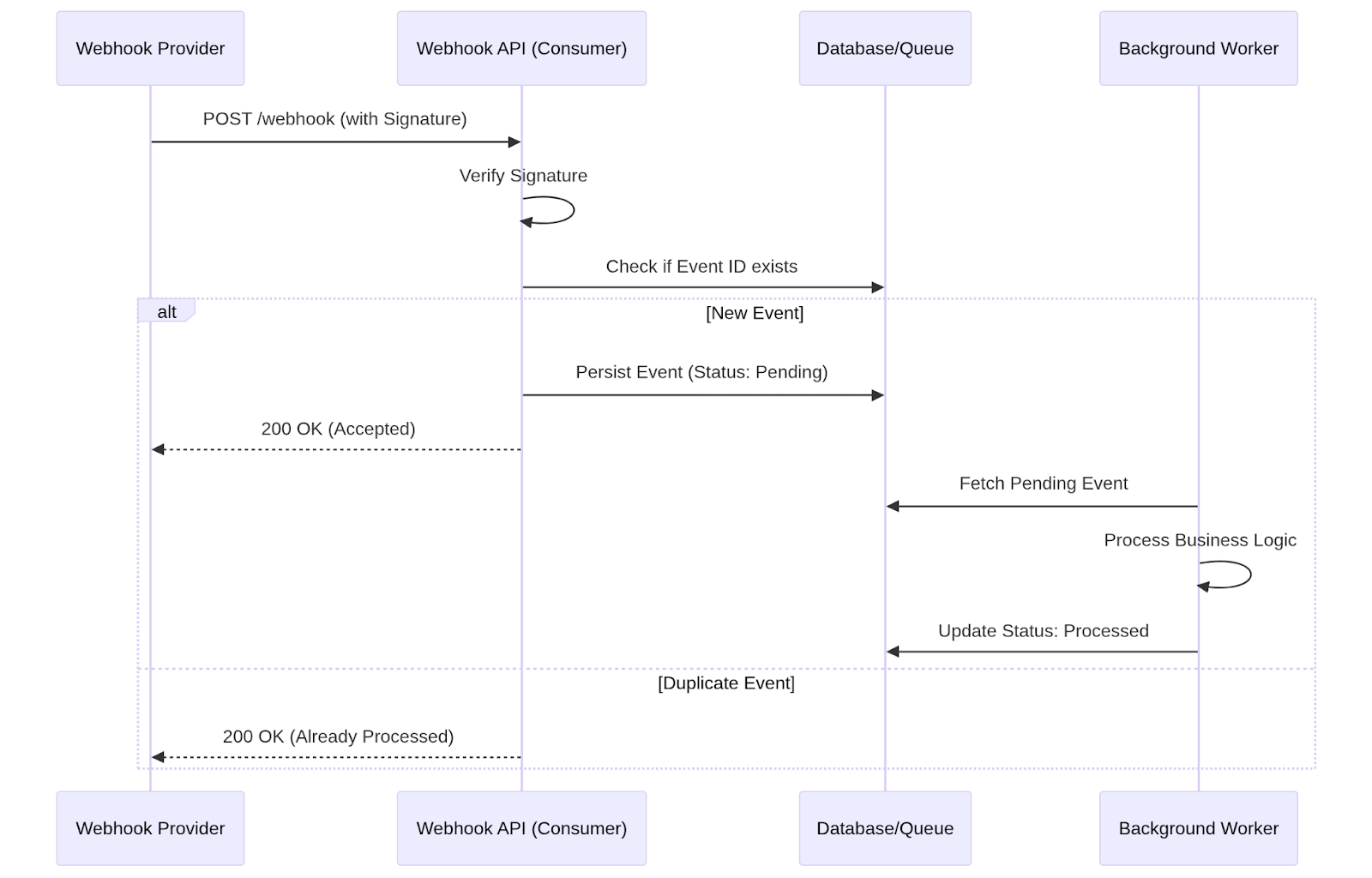
Minimalt exempel:
@app.route("/webhook", methods=["POST"])
def webhook():
event = request.get_json()
store_event(event) # Persist to DB or enqueue
return {"status": "accepted"}, 200Webhook-slutpunkten förblir snabb och förutsägbar. Tung bearbetning sker utanför förfrågans livscykel.
Detta minskar dramatiskt onödiga återförsök.
3. Offentliga slutpunkter kräver verifiering
Webhook-slutpunkter är offentligt tillgängliga per design. Vem som helst kan skicka en POST-förfrågan till dem.
Att förlita sig på dolda URL:er är inte säkert.
De flesta leverantörer inkluderar en signatur i förfrågans header som genereras med hjälp av en delad hemlighet. Konsumenten måste verifiera signaturen för att säkerställa:
- Att förfrågan faktiskt kom från leverantören
- Att nyttolasten inte manipulerades
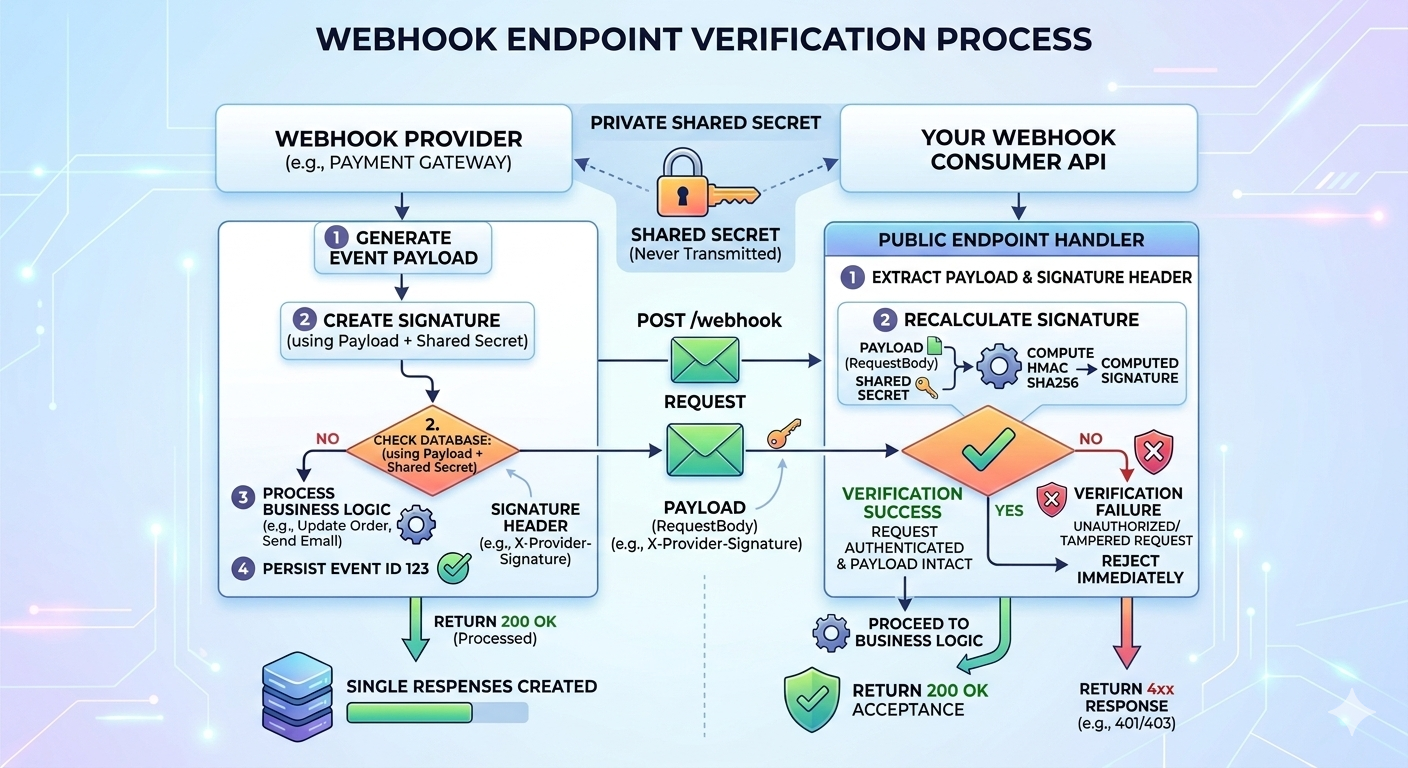
Exempel med HMAC SHA256:
import hmac
import hashlib
def verify_signature(payload: bytes, received_signature: str, secret: str) -> bool:
computed_signature = hmac.new(
secret.encode(),
payload,
hashlib.sha256
).hexdigest()
return hmac.compare_digest(computed_signature, received_signature)
Förfrågningar som misslyckas med verifieringen bör omedelbart avvisas med ett 4xx-svar.
Att hoppa över detta steg gör systemet sårbart för missbruk.
4. Händelseordning garanteras inte
Ett annat vanligt antagande: händelser anländer i den ordning de genererades.
I distribuerade system håller inte det antagandet.
Återförsök, nätverksfördröjningar och parallell leverans kan resultera i:
- Att ”Uppdatera” anländer före ”Skapa”.
- Statusövergångar visas i fel ordning.
Om din logik antar ordning, kommer du att se svårfelsökta inkonsekvenser.
Lösningen: Tillståndsmedvetna hanterare
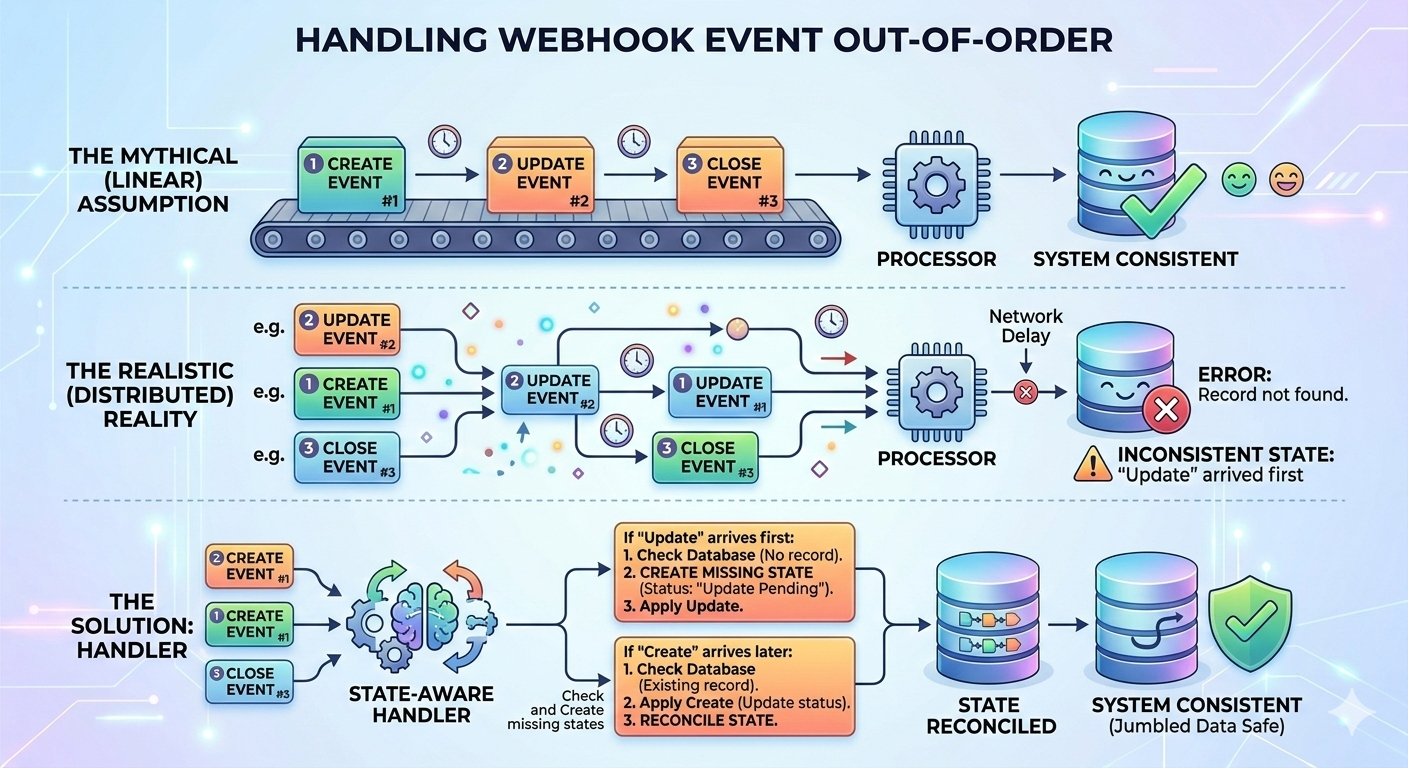
Istället för att anta ordning:
- Kontrollera om refererade entiteter existerar.
- Skapa ett saknat tillstånd om det är lämpligt.
- Ignorera eller skjut upp händelser som ännu inte kan tillämpas.
Webhook-konsumenter bör säkert stämma av tillstånd snarare än att anta korrekt sekvens.
5. Vad händer om den asynkrona uppgiften misslyckas?
Att flytta bearbetningen till en bakgrundsarbetare förbättrar tillförlitligheten, men det introducerar en ny felpunkt.
Flödet ser nu ut så här:
- Webhook anländer
- Händelsen lagras
- 200 OK returneras
- Bakgrundsjobb startar
- Bearbetningen misslyckas
Vid denna punkt kommer leverantören inte att försöka igen. Återställning blir ditt ansvar.
Om det inte hanteras korrekt leder detta till tysta inkonsekvenser.
Lägg till kontrollerade återförsök
Bakgrundsjobb bör automatiskt försöka igen vid tillfälliga fel, helst med exponentiell backoff:
@celery.task(bind=True, max_retries=5)
def process_event(self, event):
try:
handle_business_logic(event)
except TransientError as exc:
raise self.retry(exc=exc, countdown=2 ** self.request.retries)Många fel (nätverksproblem, tillfälliga låsningar) löser sig själva.
Använd en Dead Letter-strategi
Efter ett definierat antal återförsök bör misslyckade händelser flyttas till ett misslyckat tillstånd istället för att försöka igen i all oändlighet.
Lagra:
- Händelse-ID
- Rå nyttolast
- Antal återförsök
- Felmeddelande
- Status (väntande, bearbetad, misslyckad)
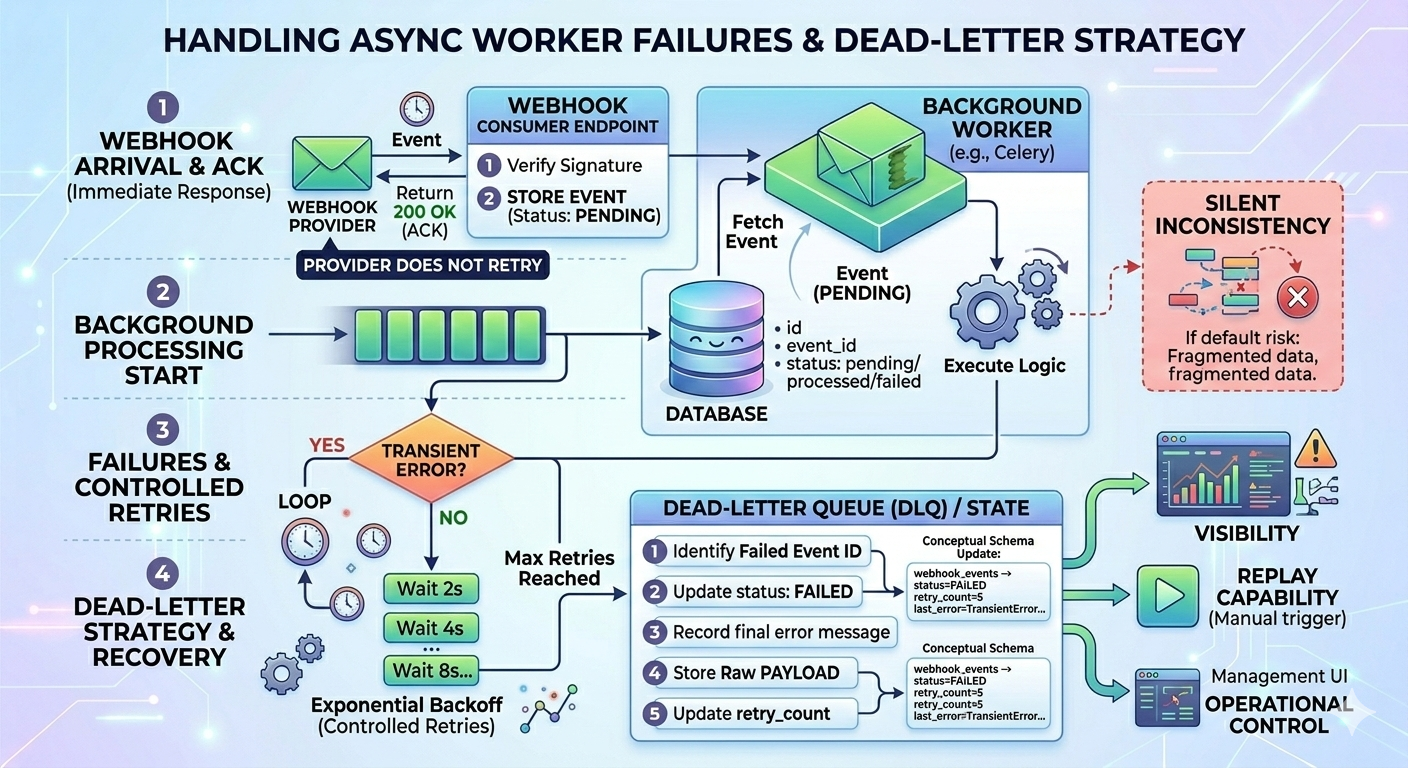
Exempel på schemakoncept:
webhook_events
--------------
id
event_id
payload (JSON)
status
retry_count
last_error
created_atDetta ger dig:
- Synlighet
- Möjlighet att spela upp igen
- Operativ kontroll
Utan detta förblir fel osynliga.
Designprinciper som håller i produktion
Efter att ha arbetat med webhook-baserade integrationer har några principer gång på gång visat sig vara värdefulla:
- Utforma varje hanterare för att tåla dubbletter
- Håll webhook-svar snabba och minimala
- Verifiera alltid förfrågans äkthet
- Anta aldrig händelseordning
- Instrumentera allt
Webhooks befinner sig vid gränsen mellan system du kontrollerar och system du inte kontrollerar. Den gränsen är där oförutsägbarheten finns.
Målet är inte att göra webhooks perfekta; det är att göra dem robusta.
Avslutande tankar
Webhooks introduceras ofta som en bekvämlighetsfunktion för integrationer. I verkligheten är de händelsestyrd kommunikation över opålitliga nätverk. Det förändrar hur de bör utformas.
När de hanteras defensivt med idempotens, asynkron bearbetning, verifiering och korrekt observerbarhet, blir webhooks stabila och förutsägbara komponenter i din arkitektur.
När de hanteras slarvigt blir de återkommande källor till subtila produktionsproblem.
Utforma för återförsök. Utforma för oordning. Utforma för fel.
Allt annat blir hanterbart.