



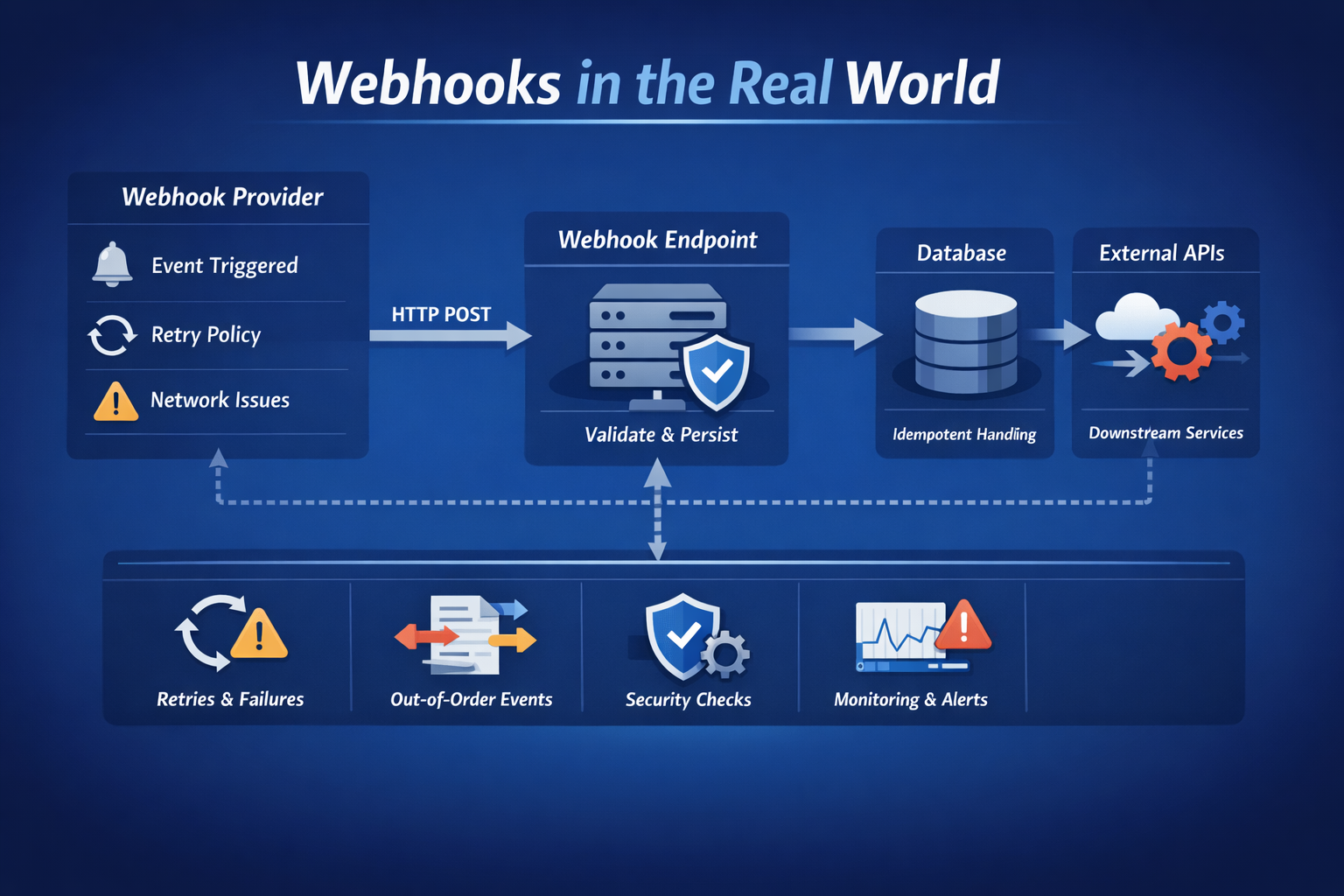
Webhooks may seem simple, but real-world integrations are messy. This blog explores how you can handle duplicates, delays, failures, and security challenges to build reliable and production-ready Webhook systems.
On paper, Webhooks look simple.
Expose an endpoint.
Receive a POST request.
Process the payload.
Return 200 OK.
That mental model works in development. It does not survive production.
Once real systems start talking to each other over unreliable networks, Webhooks stop behaving like neat HTTP requests and start behaving like distributed systems problems. Events get retried, duplicated, delayed, or reordered. If your Webhook consumer assumes perfect conditions, it will eventually break.
Here’s what tends to go wrong and the patterns that make Webhook handling reliable.
1. Duplicate Events Are Not a Bug - They’re Expected
Most webhook providers retry delivery if:
- Your endpoint times out
- A non-2xx status code is returned
- There’s a transient network issue
That means the same event can arrive multiple times.
If each delivery triggers business logic blindly, you’ll eventually see duplicated records, an inconsistent state, or repeated side effects.
The Fix: Idempotency
Webhook handlers must be idempotent; processing the same event multiple times should not change the final result.
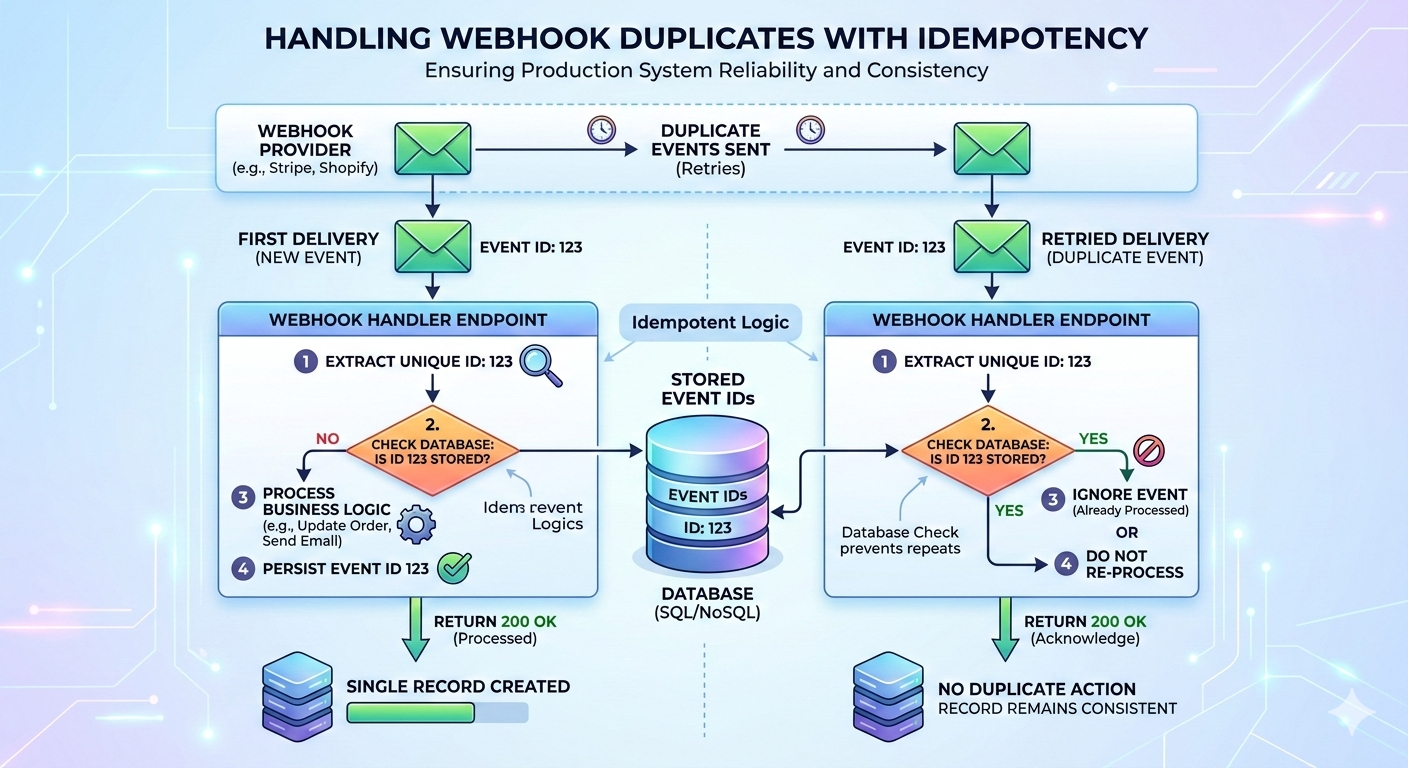
The simplest way to achieve this is:
- Ensure each event has a unique identifier
- Store processed event IDs
- Ignore events that were already handled
Example (Flask + SQLAlchemy pattern):
def handle_webhook(event):
event_id = event["id"]
if db.session.query(WebhookEvent)
.filter_by(event_id=event_id).first():
return {"status": "already_processed"}, 200
process_event(event)
db.session.add(WebhookEvent(event_id=event_id))
db.session.commit()
return {"status": "processed"}, 200With this in place, retries become harmless. Without it, retries become incidents.
2. Processing Everything Inside the Request Is Risky
It’s tempting to do all business logic directly inside the webhook route:
- Validate payload
- Update database
- Call downstream services
- Trigger workflows
That works until the load increases.
If processing takes too long, the provider may assume failure and retry even if your system is still working. This increases traffic, which slows processing further, creating a feedback loop.
The Fix: Acknowledge Fast, Process Asynchronously
A more resilient pattern is:
- Validate the request
- Persist the raw event (database or queue)
- Immediately return 200 OK
- Process the event in a background worker
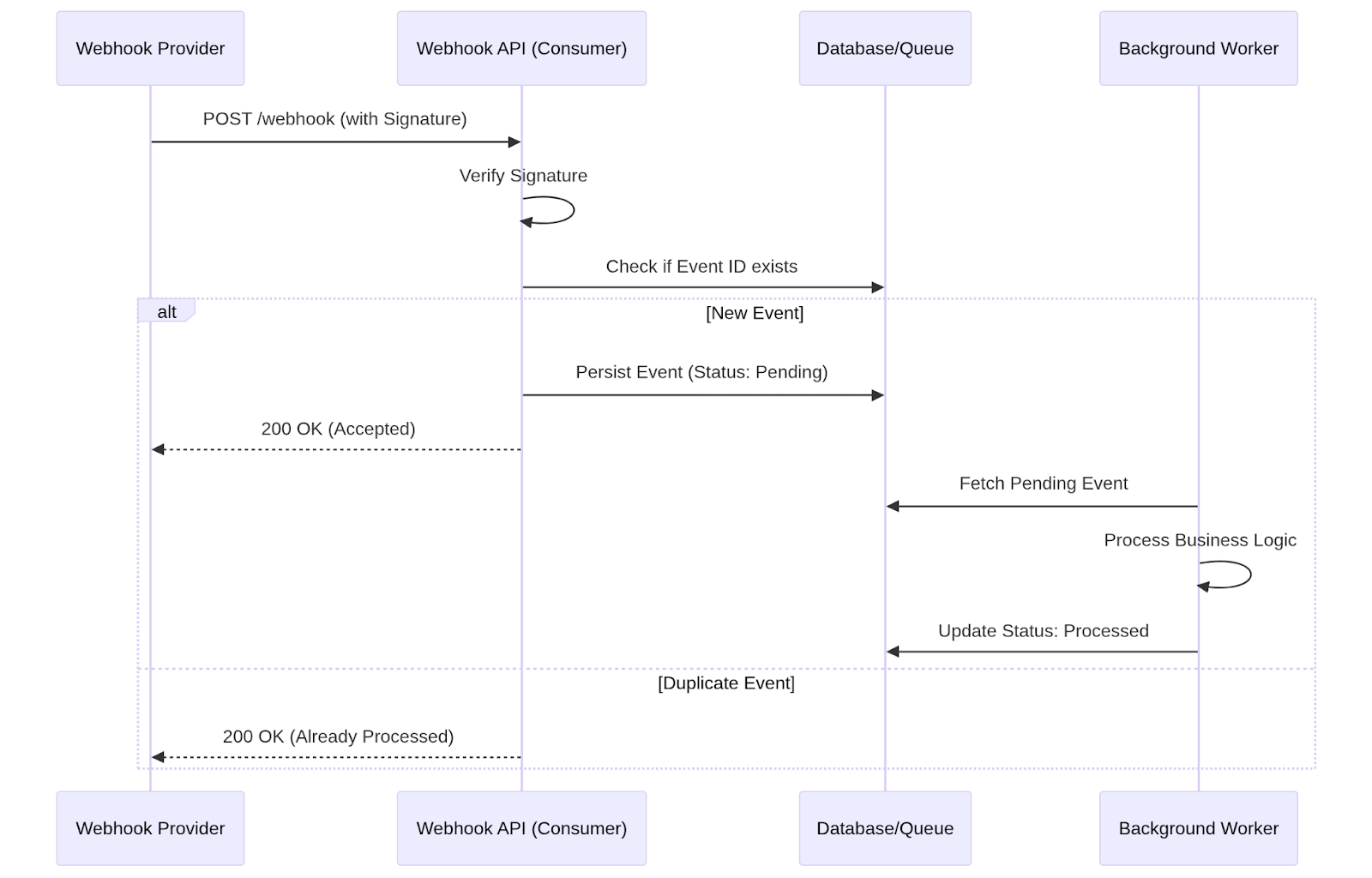
Minimal example:
@app.route("/webhook", methods=["POST"])
def webhook():
event = request.get_json()
store_event(event) # Persist to DB or enqueue
return {"status": "accepted"}, 200The webhook endpoint stays fast and predictable. Heavy processing happens outside the request lifecycle.
This dramatically reduces unnecessary retries.
3. Public Endpoints Require Verification
Webhook endpoints are publicly accessible by design. Anyone can send a POST request to them.
Relying on hidden URLs is not secure.
Most providers include a signature request header generated using a shared secret. The consumer must verify that the signature to ensure:
- The request actually came from the provider
- The payload wasn’t tampered with
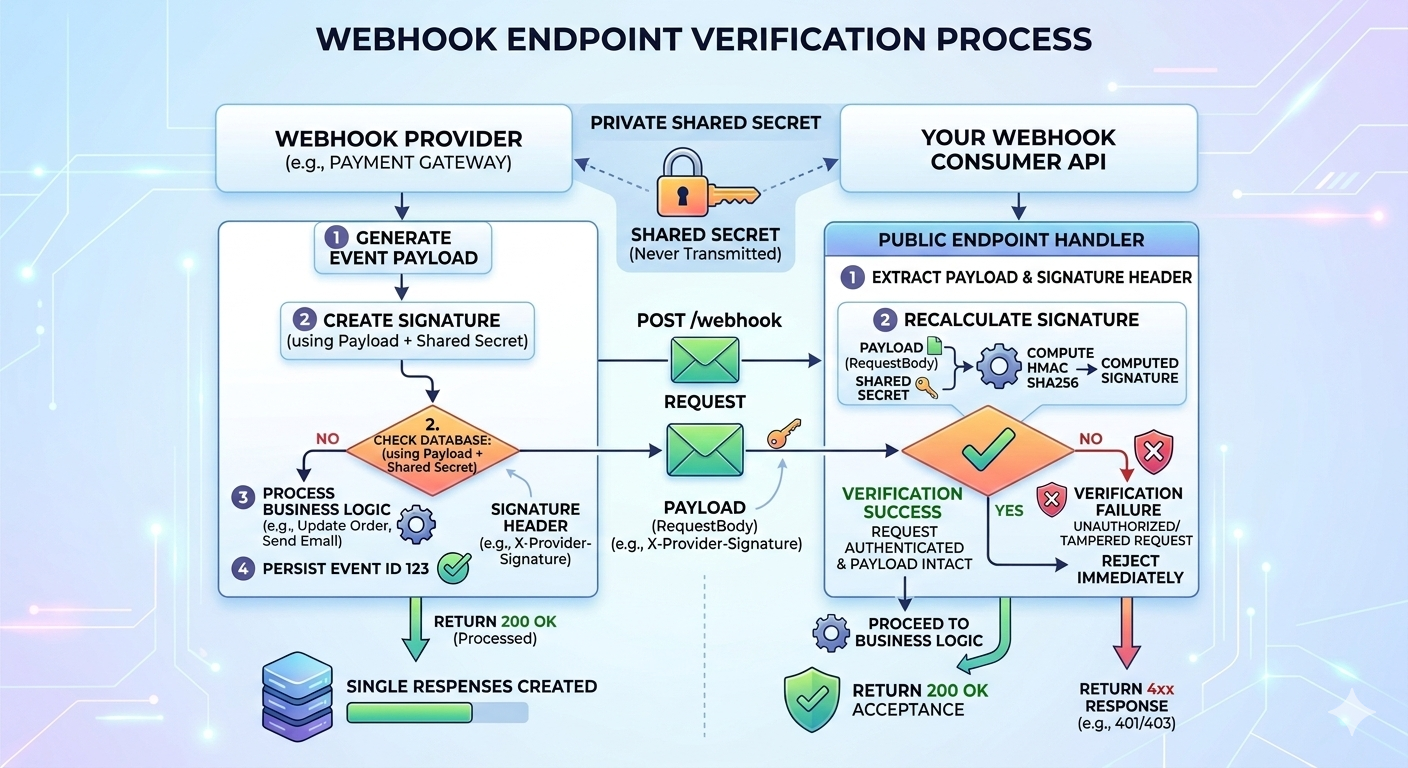
Example using HMAC SHA256:
import hmac
import hashlib
def verify_signature(payload: bytes, received_signature: str, secret: str) -> bool:
computed_signature = hmac.new(
secret.encode(),
payload,
hashlib.sha256
).hexdigest()
return hmac.compare_digest(computed_signature, received_signature)
Requests failing verification should be rejected immediately with a 4xx response.
Skipping this step leaves the system open to abuse.
4. Event Order Is Not Guaranteed
Another common assumption: events arrive in the order they were generated.
In distributed systems, that assumption doesn’t hold.
Retries, network delays, and parallel delivery can result in:
- “Update” arriving before “Create”.
- Status transitions are appearing out of sequence.
If your logic assumes ordering, you’ll see hard-to-debug inconsistencies.
The Fix: State-Aware Handlers
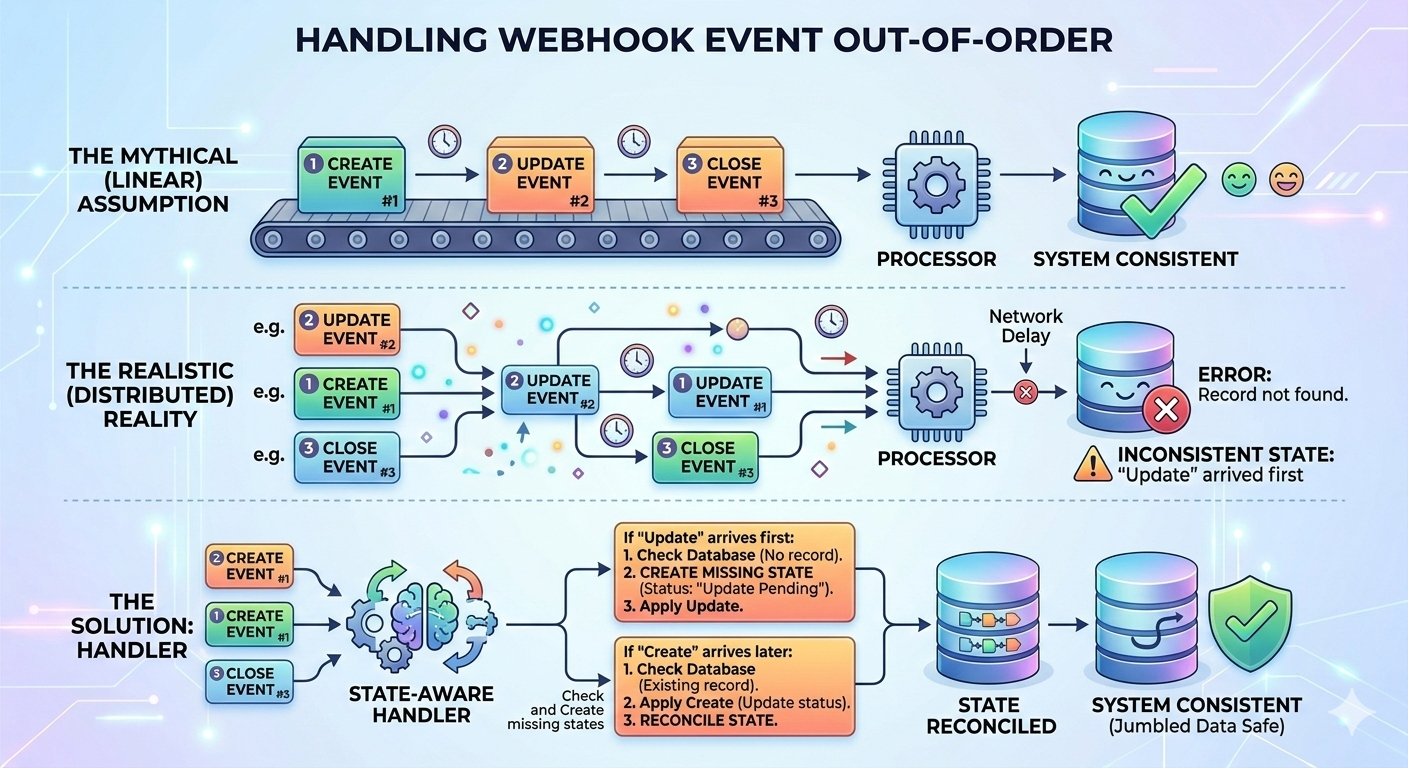
Instead of assuming order:
- Check whether referenced entities exist.
- Create a missing state if appropriate.
- Ignore or defer events that cannot yet be applied.
Webhook consumers should reconcile state safely rather than assume sequence correctness.
5. What If the Async Task Fails?
Moving processing to a background worker improves reliability, but it introduces a new failure point.
Flow now looks like this:
- Webhook arrives
- The event is stored
- 200 OK is returned
- Background job starts
- Processing fails
At this point, the provider will not retry. Recovery becomes your responsibility.
If not handled properly, this leads to silent inconsistencies.
Add Controlled Retries
Background jobs should retry transient failures automatically, ideally with exponential backoff:
@celery.task(bind=True, max_retries=5)
def process_event(self, event):
try:
handle_business_logic(event)
except TransientError as exc:
raise self.retry(exc=exc, countdown=2 ** self.request.retries)Many failures (network issues, temporary locks) resolve themselves.
Use a Dead Letter Strategy
After a defined number of retries, failed events should move to a failed state rather than retry forever.
Store:
- Event ID
- Raw payload
- Retry count
- Error message
- Status (pending, processed, failed)
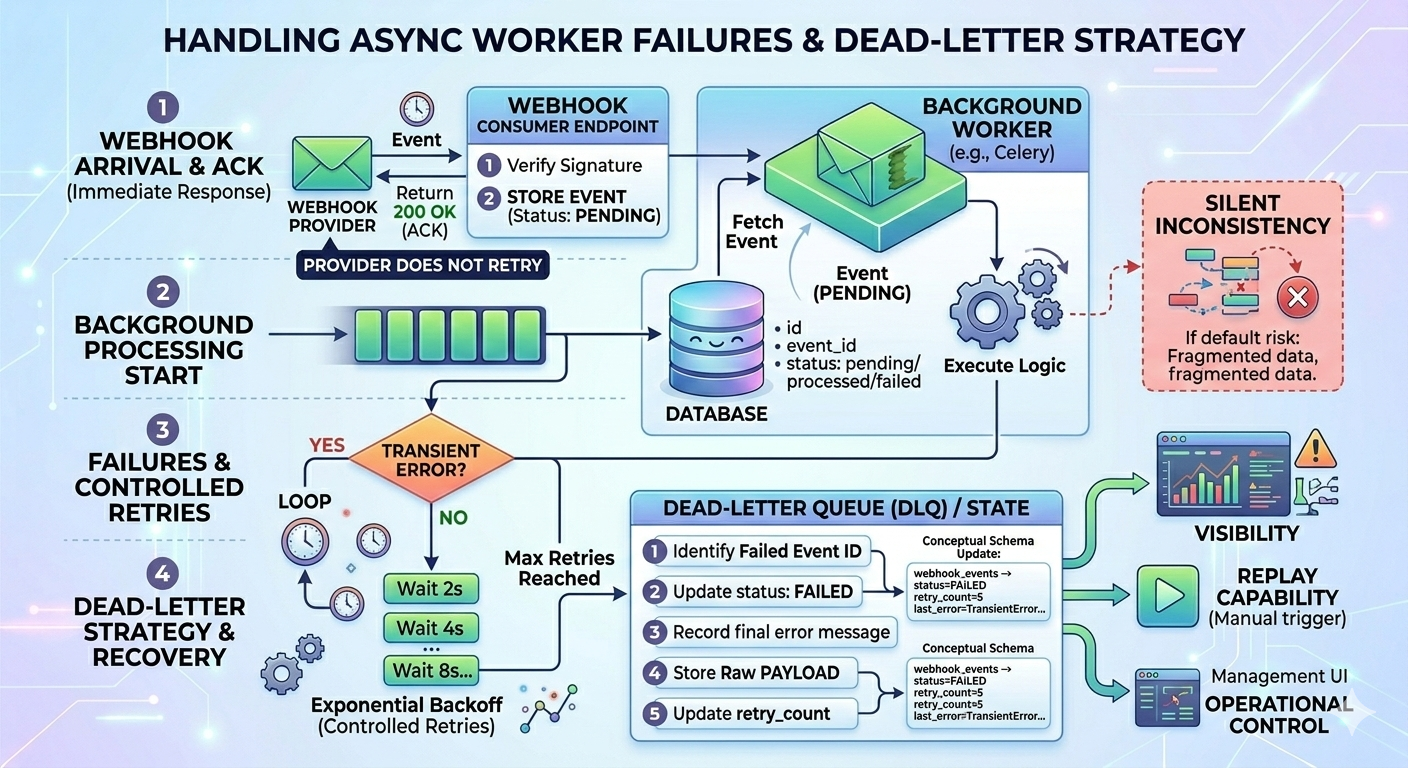
Example schema concept:
webhook_events
--------------
id
event_id
payload (JSON)
status
retry_count
last_error
created_atThis gives you:
- Visibility
- Replay capability
- Operational control
Without this, failures remain invisible.
Design Principles That Hold Up in Production
After working with webhook-based integrations, a few principles consistently prove valuable:
- Design every handler to tolerate duplicates
- Keep webhook responses fast and minimal
- Always verify request authenticity
- Never assume event ordering
- Instrument everything
Webhooks sit at the boundary between systems you control and systems you don’t. That boundary is where unpredictability lives.
The goal isn’t to make webhooks perfect; it’s to make them resilient.
Final Thoughts
Webhooks are often introduced as a convenience feature for integrations. In reality, they are event-driven communication over unreliable networks. That changes how they should be designed.
When treated defensively with idempotency, async processing, verification, and proper observability, webhooks become stable and predictable components of your architecture.
When treated casually, they become recurring sources of subtle production issues.
Design for retries. Design for disorder. Design for failure.
Everything else becomes manageable.
